在软件测试领域,测试用例设计是核心技能之一。无论你是手工测试还是自动化测试,编写高质量的测试用例都是确保软件质量的关键。今天,我们将重温三种最经典的黑盒测试方法:等价类划分、边界值分析和判定表,并通过一个常见的登录功能实例,展示如何将这些方法应用到实际测试工作中。
为什么测试用例设计如此重要?
在深入讨论具体方法前,先思考一个问题:为什么我们需要系统化的测试用例设计方法?
想象一下,如果测试用例只是随机设计的,会发生什么?我们可能会遗漏重要场景,重复测试相同功能,或者浪费资源在无关紧要的测试上。系统化的测试用例设计方法可以帮助我们:
-
提高测试覆盖率
-
减少测试用例数量同时保持测试效果
-
更有效地发现缺陷
-
使测试过程更加标准化和可重复
接下来,让我们逐一探讨这三种经典的黑盒测试方法。
等价类划分(Equivalence Partitioning)
基本概念
等价类划分是一种系统性的测试用例设计技术,其核心思想是将输入数据划分为若干个等价类,使得同一等价类中的数据进行测试会得到相同的结果。换句话说,如果程序处理等价类中的一个数据是正确的,那么它处理该等价类中的其他数据也应该正确。
划分原则
-
有效等价类:符合程序输入要求的合理数据集合,用于验证程序是否实现了预期功能。
-
无效等价类:不符合程序输入要求的不合理数据集合,用于验证程序的异常处理能力。
实际应用
假设我们有一个输入框要求输入1-100的整数,根据等价类划分,我们可以将其分为:
-
有效等价类:1-100之间的整数
-
无效等价类:小于1的整数、大于100的整数、非整数
通过这种方法,我们不需要测试1-100之间的每一个值,而只需从每个等价类中选取少量代表值进行测试。
边界值分析(Boundary Value Analysis)
基本概念
边界值分析是基于经验的测试技术,其核心观点是错误更可能发生在输入域的边界处,而不是中心区域。这种方法与等价类划分紧密结合,重点关注边界条件。
边界确定
对于任何有范围的输入,边界通常包括:
-
最小值
-
略高于最小值
-
正常值
-
略低于最大值
-
最大值
实际应用
继续使用上面的例子(输入1-100的整数),根据边界值分析,我们应该测试:
-
最小值:1
-
略高于最小值:2
-
正常值:50
-
略低于最大值:99
-
最大值:100
-
刚好低于最小值:0
-
刚好高于最大值:101
经验表明,边界值分析能非常有效地发现潜在缺陷,因为开发人员经常在边界条件处理上犯错。
判定表(Decision Table)
基本概念
判定表适用于处理多个输入条件组合决定多个动作的复杂业务逻辑。它能够系统性地覆盖所有可能的条件组合,确保不会遗漏任何重要场景。
判定表结构
判定表由四部分组成:
-
条件桩:列出所有输入条件
-
动作桩:列出所有可能采取的操作
-
条件项:针对条件桩给出的条件进行取值
-
动作项:列出在条件项的各种取值情况下应采取的动作
实际应用
判定表特别适合测试复杂的业务规则,如折扣计算、权限控制等。通过判定表,我们可以确保覆盖所有可能的条件组合,这是手动选择测试场景时容易忽略的。
实战演练:登录功能测试用例设计
现在,让我们通过一个常见的登录功能,展示如何综合运用这三种测试方法。
功能需求说明
假设我们有一个系统的登录功能,包含以下规则:
-
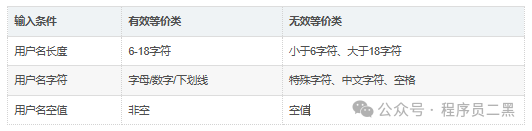
用户名长度为6-18个字符,只能包含字母、数字和下划线
-
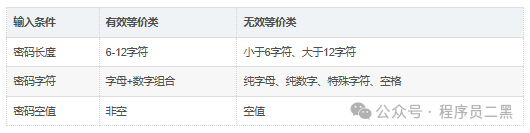
密码长度为6-12个字符,至少包含字母和数字
-
用户有连续登录失败次数限制,最多5次,超过则账号被锁定30分钟
-
登录成功时记录日志并跳转到首页
-
登录失败时显示相应错误信息
等价类划分应用
首先,我们对用户名和密码字段进行等价类划分:
用户名等价类划分:
密码等价类划分:
边界值分析应用
接下来,我们对用户名和密码长度进行边界值分析:
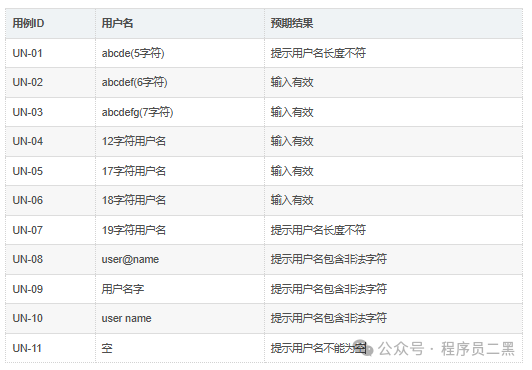
用户名长度边界值:
-
刚好低于最小值:5个字符
-
最小值:6个字符
-
略高于最小值:7个字符
-
正常值:12个字符
-
略低于最大值:17个字符
-
最大值:18个字符
-
刚好高于最大值:19个字符
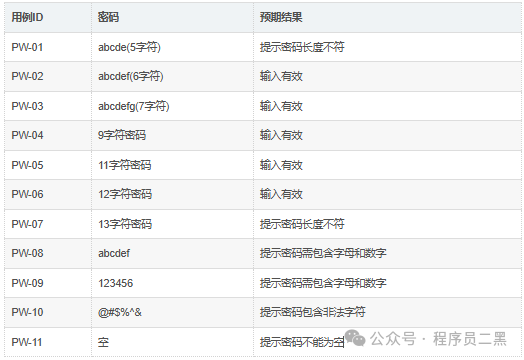
密码长度边界值:
-
刚好低于最小值:5个字符
-
最小值:6个字符
-
略高于最小值:7个字符
-
正常值:9个字符
-
略低于最大值:11个字符
-
最大值:12个字符
-
刚好高于最大值:13个字符
判定表应用
现在,我们使用判定表来处理登录尝试的各种情况:
登录判定表:

注意:实际判定表会更复杂,这里做了简化以展示基本思路。
综合测试用例设计
基于以上分析,我们可以设计出一系列测试用例:
用户名测试用例:
密码测试用例:
登录场景测试用例:

在API测试中的应用
这些测试设计方法不仅适用于UI测试,同样适用于API测试。以登录API为例:
POST /api/loginContent-Type: application/json{"username": "testuser","password": "testpass123"}
我们可以设计相同的测试用例,只是验证方式从检查UI变为检查API响应:
-
测试有效等价类时,期望返回200状态码和认证成功的响应
-
测试无效等价类时,期望返回400或401状态码和相应的错误信息
-
测试边界值时,验证API对边界输入的处理
-
使用判定表测试不同条件组合下的API响应
在单元测试中的应用
等价类划分、边界值分析和判定表同样适用于单元测试。以用户名校验函数为例:
def validate_username(username):"""验证用户名是否合法要求:长度6-18字符,只包含字母、数字和下划线"""if len(username) < 6 or len(username) > 18:return Falseif not re.match(r'^[a-zA-Z0-9_]+$', username):return Falsereturn True
针对这个函数,我们可以设计以下单元测试:
import pytestclass TestUsernameValidation:# 等价类测试def test_valid_username(self):assert validate_username("validuser123") == Truedef test_username_with_special_chars(self):assert validate_username("user@name") == False# 边界值测试def test_username_min_length(self):assert validate_username("abcdef") == True # 6字符,最小值def test_username_below_min(self):assert validate_username("abcde") == False # 5字符,低于最小值def test_username_max_length(self):assert validate_username("abcdefghijklmnopqr") == True # 18字符,最大值def test_username_above_max(self):assert validate_username("abcdefghijklmnopqrs") == False # 19字符,高于最大值
测试用例设计的最佳实践
在实际应用中,结合多种测试设计方法可以获得更好的效果。以下是一些最佳实践:
-
先使用等价类划分,将输入域划分为几个互不相交的子集
-
然后应用边界值分析,重点关注每个等价类的边界情况
-
对于复杂业务逻辑,使用判定表确保覆盖所有条件组合
-
不要忘记无效等价类,它们常常能发现更多的缺陷
-
考虑使用 pairwise 或组合测试技术,当输入参数较多时,覆盖所有组合不现实,可以使用这些技术选择有代表性的测试用例
-
定期评审和更新测试用例,随着需求变化,测试用例也需要相应调整
总结
等价类划分、边界值分析和判定表是测试用例设计中最基础也最重要的三种方法。它们不仅适用于手工测试,也适用于自动化测试、API测试和单元测试。
通过系统化地应用这些方法,我们可以:
-
用更少的测试用例覆盖更多的场景
-
提高测试效率和效果
-
更早地发现潜在缺陷
-
建立更可靠的测试过程
测试用例设计是一门艺术,需要测试人员在理解这些基本方法的基础上,结合具体业务场景灵活应用。只有通过不断实践和总结,才能设计出既高效又有效的测试用例,真正保证软件质量。
希望本文能帮助你重新认识这些经典的测试设计方法,并在实际工作中灵活运用。如果你有更好的实践经验或想法,欢迎交流分享!
本文原创于【程序员二黑】公众号,转载请注明出处!
欢迎大家关注笔者的公众号:程序员二黑,专注于软件测试干活分享,全套测试资源可免费分享!
最后如果你想学习软件测试,欢迎加入笔者的交流群:785128166,里面会有很多资源和大佬答疑解惑,我们一起交流一起学习!